The FileMaker platform is super flexible and makes it incredibly easy to start building custom software quickly. Yet it’s this very feature that too often leads to coding nightmares: poorly planned development, code that is difficult to understand or translate to other developers, and solutions that become difficult and costly to maintain long-term. Years after it was created, it is easy to forget how a solution was developed, even if the solution has never changed hands, and the more complex an app becomes, the more likely it is to break because of forgotten or invisible dependencies. If the solution does change hands, it can be more difficult to decipher.
We strive to evolve our development systems and processes to minimize these scenarios. One way we’ve done that is to create and train developers on a development framework for our FileMaker solutions based on software industry best practices and innovative FileMaker-specific practices that vastly reduce dependencies and code redundancy. We perpetually refine our framework to allow us to create apps that are easy to modify and maintain, while retaining enough flexibility to take full advantage of FileMaker’s rapid development features for customizing software to serve our clients’ unique organizations.
Our framework borrows from the time-tested principles of the model-view-controller (MVC) design pattern and object-oriented programming (OOP). These principles allow us to organize and code solutions in a way that is modular, easily extensible, and self-documenting. More specifically, many of the ideas on which our framework is based come from WebObjects, Apple’s integrated suite of Java frameworks for rapidly developing scalable, sophisticated Internet and Enterprise applications. Apple no longer sells WebObjects, but we have done our best to adapt some of the brilliance behind that suite of tools to FileMaker development.
Below is a brief overview of how we use MVC and OOP principles along with standardized methods in FileMaker to reduce code redundancy in our solutions to prevent our code from becoming a nightmare for our clients.
Model-View-Controller Design Pattern
The MVC design pattern separates a software solution into 3 parts: the Model, which describes the structure and characteristics of data stored and used by the solution, the View, or the visual presentation of information to a user, and the Controller, which controls how the Model, View and the user of the solution interact.
In the FileMaker platform, the Model is most closely represented by the tables, fields, and relationship graph that describe the data in a solution. The View is most closely represented by layouts and layout elements that allow a user to interact with the solution. The Controller is most closely represented by the built-in FileMaker functionality and custom built scripts that allow a user to use layout elements to create, modify or delete the data and control the way data is displayed to the user.
The advantages of using the MVC pattern include:
- Better organization of the Controller into logical groups based on functionality of the interface on screen layouts (View) and the data structure in the Model so that the solution can be self-documenting with minimal effort.
- Allowing layouts (Views) built for different purposes (iOS vs. Web vs. Desktop, for example) to use the same dataset without complicating the same interface file.
- Making modifications and updates to the Views simpler because they can be switched out easily without affecting the underlying data model.
Object Oriented Programming Principles
The acronym “SOLID” describes the following five basic principles of object-oriented programming, summarized by Robert C. Martin in his paper Design Principles and Design Patterns.
- Single Responsibility Principle: a class, or template representation of an object in the real world, should have only a single responsibility.
- Open/Closed Principle: software entities should be open for extension but closed for modification, meaning elements of software should allow extensibility without having to be modified.
- Liskov Substitution Principle: objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.
- Interface Segregation Principle: many client-specific interfaces are better than one general-purpose interface
- Dependency Inversion Principle: High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.
The intention behind these cryptic-sounding principles is to make software design more understandable, flexible and maintainable. Many modern programming languages follow the principles of OOP to varying degrees. Though the FileMaker platform is not a programming language of this sort, we’ve found that the principles of OOP still provide ways to make our solutions more understandable, flexible and maintainable.
How We Use MVC and OOP in the FileMaker Platform
Because FileMaker combines layouts, scripts, and data structure into one integrated development platform, it is not possible to completely separate the Controller out of a FileMaker solution, since some of the Controller is built into FileMaker itself. Instead, we use what’s commonly known in the FileMaker developer community as the data separation model to separate our solutions into at least 2 files: the data (model) and one or more interface (view) files, and divide the scripts (controller) between them.
Data File: the Model (and Controller)
Scripts in the data, or Model, file are organized as “methods” describing table “classes” in the data model:
- Since the introduction of the unified file system in version 7 of the FileMaker platform about a decade ago, we’ve been using what’s now known as the “selector connector” method in the FileMaker developer community to design the FileMaker relationship graph and keep our scripts context-free. We also use the full name of the table in our Table Occurrences so no one has to guess what our abbreviations stand for. Less guessing leads to faster development with fewer mistakes.
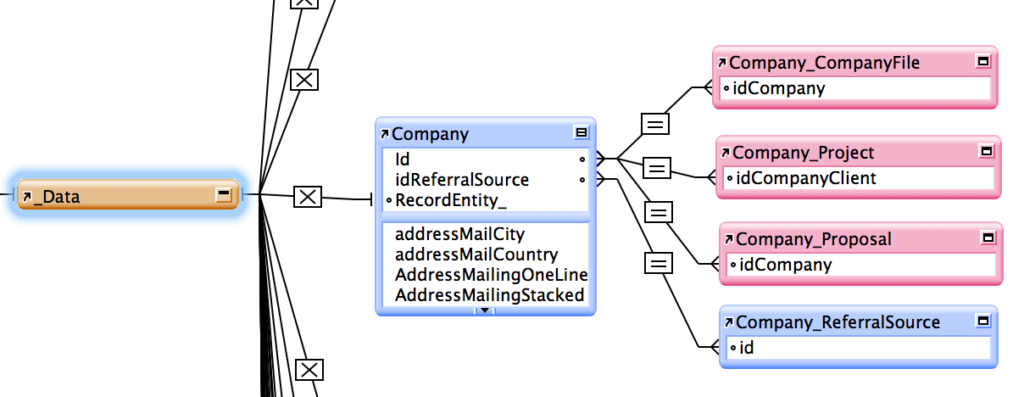
Context-Independent Data Modeling in FileMaker
CRUD in the general software world stands for the basic functions performed on persistent data: Create, Read, Update, and Delete. FileMaker renders the “read” action moot because we are always able to “read” the data by placing fields on a layout. CRUD in our framework substitutes “read” with “report”, because we keep reports and charts in the data file. Displaying reports and charts is the only functionality that exposes the data file to user interaction.
A set of scripts control CRUD (create, report, update, and delete) functionality. This means all records in our FileMaker solutions are created, edited and deleted in a standardized way that minimizes bugs resulting from code repetition. This method of organizing scripts allows us to abstract the basic functions of persistent data and attempts to mimic what’s called Enterprise Object (EO) modeling in OOP. The main purpose of doing it this way is to organize scripts so it’s simpler to document our clients’ business rules within the code structure itself.

- Our scripts are named as commands that succinctly describe what they do. You may have also noticed that our script names in the image above explicitly name parameters, and clearly identify which parameters are required vs. optional. Multiple named parameters are passed into a script and script results are passed back to any calling script in a consistent way, using a standard set of custom functions and script steps. This “black box” method of abstraction provides a few advantages:
- It eliminates the majority of dependencies that create a tremendous amount of confusion and time spent tracing long, complex scripts written by other developers or even ourselves.
- It minimizes the need to look inside subscripts to see how they work.
- It makes scripting more modular and reusable, so that it’s easier to extend functionality.
- It allows vastly better error handling by eliminating the need for a complex nest of conditional statements to capture errors.
Another set of scripts represent tables in the data Model, with a folder for each table and the scripts within that folder written as if they are methods describing an object class with the table name. The scripts within those folders further describe the table “class”. These scripts, along with a standard set of field naming conventions, allow us to create the abstraction needed to avoid having to rewrite repetitive script steps to create, update and delete records in each table of the solution.
Any custom functionality for CRUD behavior is written by extending the functionality of the standard CRUD scripts without having to modify them. Scripts in the data file are abstracted black boxes that accept parameters and return one or more results without ever needing user interaction or detailed knowledge about the code inside them.
The parts of the Controller that may also be in the data file are a set of scripts for the user session, reports, security, server schedules, and integration with other software solutions.
Interface File(s): the View (and Controller)
- We use standardized scripts to control interface components, including email, fields, layouts, navigation, record control, user input, and windows. This minimizes code redundancy, which reduces the possibility of introducing bugs into the solution and makes it easier to find and fix them when they do appear.
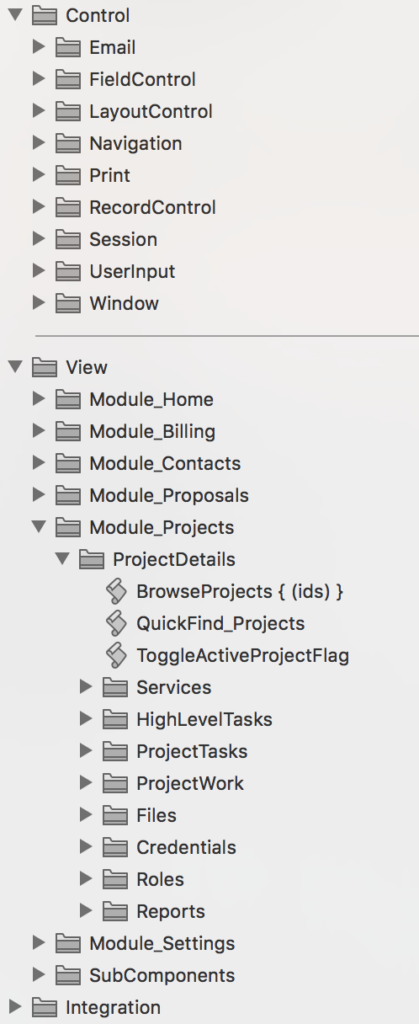
Script Organization in the Interface File
- Scripts that are kept in the interface files are limited to only those which control user interaction. There are no CRUD-related scripts in the interface file. This is an important part of the MVC design pattern which enables multiple interface files to use the same data file. Data stored in the data file is not manipulated from interface files. Instead, interface files call the CRUD scripts in the data file to modify records stored there.
- The remaining scripts in the interface files are organized by modules, or screen/layout groups, layouts and layout subcomponents. This method of organizing scripts makes them easy to find, auto-documents the structure of the interface, which makes it harder to forget how it was created and makes it much easier to maintain the solution in the long run.
- Because the parameters are in the script names, developers coding in the interface files don’t need to delve into the code in the data file to be able to understand or use the CRUD scripts. This makes development simpler, more efficient, and less prone to bugs.
- Other parts of the Controller that may be in the View files are a set of scripts for security scripts, server schedules, and integration with other software solutions.
Our Development Framework Provides Extra Value to Our Clients
Beyond the above, we use consistent naming conventions for fields in our tables as well as our scripts, and consistent ways of designing our user interfaces to make reuse of layout components simple and efficient. We also use some FileMaker-specific tricks, such as defining business logic for record creation and deletion in the table definition itself to make the framework self-documenting and work flawlessly. I’ll be writing more about these tips and tricks soon.
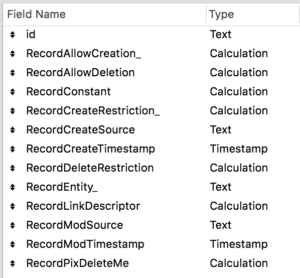
Standard Field Naming Conventions with Built-In Business Logic
In summary, the FileMaker platform already makes custom app development quicker and simpler than other ways of programming software. Using our development framework does require at least a basic understanding of MVC and OOP principles. Yet the learning curve is worth the effort of training our developers because of the following benefits it brings to our clients:
- Our code has fewer bugs and requires less maintenance due to less repetitive code. The inevitable bugs that do exist are easier to find and fix.
- Feature modifications are simpler to add due to the framework’s self-documenting structure, scripts that remain independent of each other, and a clear organization in the data and interface files.
- Consistent development practices make it easy to explain and share work with developers when a project is big enough that we need to hire help.